本記事では vSphere HA (High Availability) の設定および動作確認について解説します.
vSphere HA によってホストやストレージ,仮想マシンの障害が発生した場合に仮想マシンを有効なホストで再起動させることでサービスのダウンタイムを少なくすることができます.
vSphere HA の説明については「VMware vSphere – vSphere HA の説明」で解説していますので合わせてご参照ください.
- VMware vSphere に関するお話
- VMware vSphere – ESXi インストール
- VMware vSphere – 仮想スイッチ/ポートグループの設定
- VMware vSphere – NFSデータストアの追加
- VMware vSphere – vCenter Server のインストール
- VMware vSphere – vCenter Server の初期設定
- VMware vSphere – ローカルデータストアの追加
- VMware vSphere – EVC (Enhanced vMotion Compatibility)
- VMware vSphere – 分散仮想スイッチ (分散仮想スイッチの説明,作成)
- VMware vSphere – 分散仮想スイッチ (アップリンクの付け替え,VMkernel インターフェイスの移行)
- VMware vSphere – 分散仮想スイッチ (仮想マシンポートグループの移行,アップリンクの完全付け替え)
- VMware vSphere – iSCSI ストレージのマウント (マウントに向けた準備)
- VMware vSphere – iSCSI ストレージのマウント
- VMware vSphere – ライブマイグレーション (vMotion と Storage vMotion)
- VMware vSphere – ライブマイグレーション(vMotion) のトラブルシュート
- VMware vSphere – vSphere DRS (Distributed Resource Scheduler) 概要
- VMware vSphere – vSphere DRS 設定 (DRS 手動)
- VMware vSphere – vSphere DRS 設定 (DRS 一部自動化)
- VMware vSphere – vSphere DRS 設定 (DRS 完全自動化)
- VMware vSphere – vSphere DRS 設定 (アフィニティとアンチアフィニティ)
- VMware vSphere – vSphere DRS 設定 (ホストアフィニティ)
- VMware vSphere – vSphere HA の説明
- VMware vSphere – vSphere HA の設定
- VMware vSphere – vSphere HA の障害時動作の確認
- VMware vSphere – vCenter Server Appliance のアップデート・アップグレード
- VMware vSphere – ESXi のアップデート・アップグレード – Life Cycle Manager 経由
- VMware vSphere – ESXi のアップデート・アップグレード – CD-ROM 経由
VMware vSphere – vSphere HA の設定
「ホストおよびクラスタ」より vSphere HA を設定するクラスターを選択,画面中央の「設定」をクリック,「サービス」-「vSphere の可用性」を選択して「編集」クリックします.
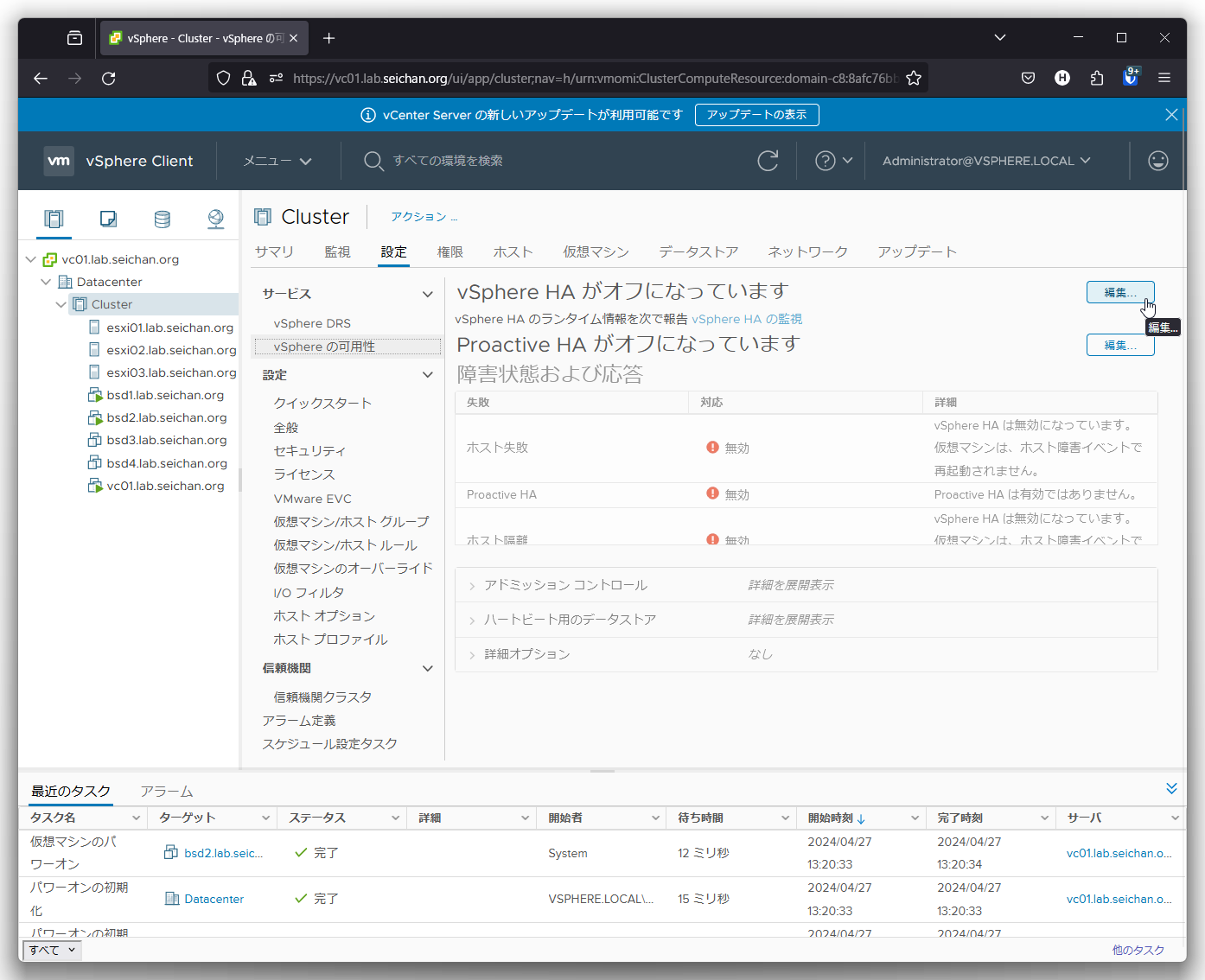
画面上部の「vSphere HA」のスイッチをクリックして有効にします.そうすると他の項目のグレーアウトが解除されます.
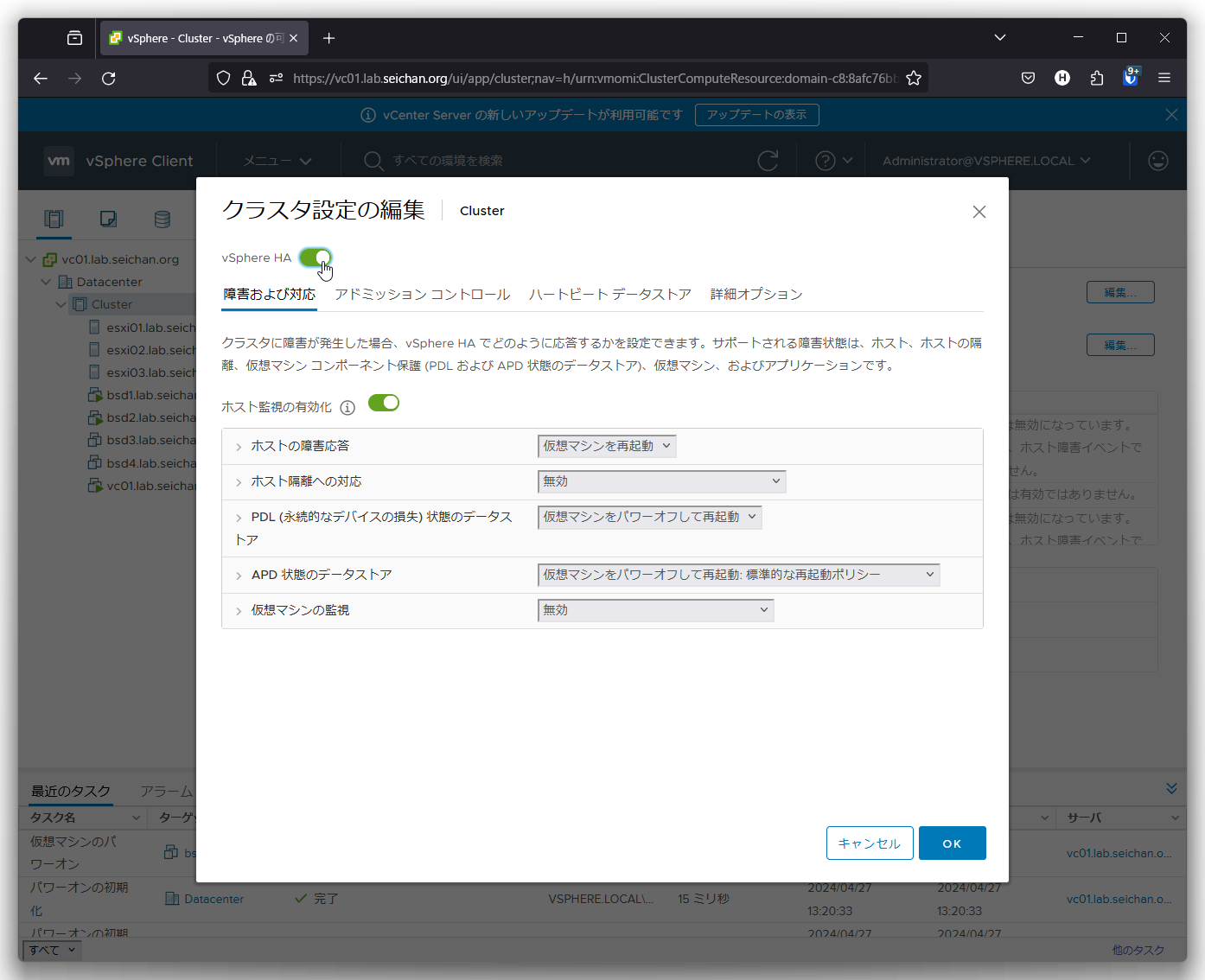
障害及び対応
障害が発生した際の挙動を設定する項目となります.詳細は「VMware vSphere – vSphere HA の説明」を参照してください.
ホストの障害応答
ホストに障害が発生した際の仮想マシンの挙動を設定します.
- 無効
仮想マシンの再起動は行いません - 仮想マシンを再起動
デフォルト値です.ホスト障害が検知された場合,仮想マシンを他のホストで再起動します
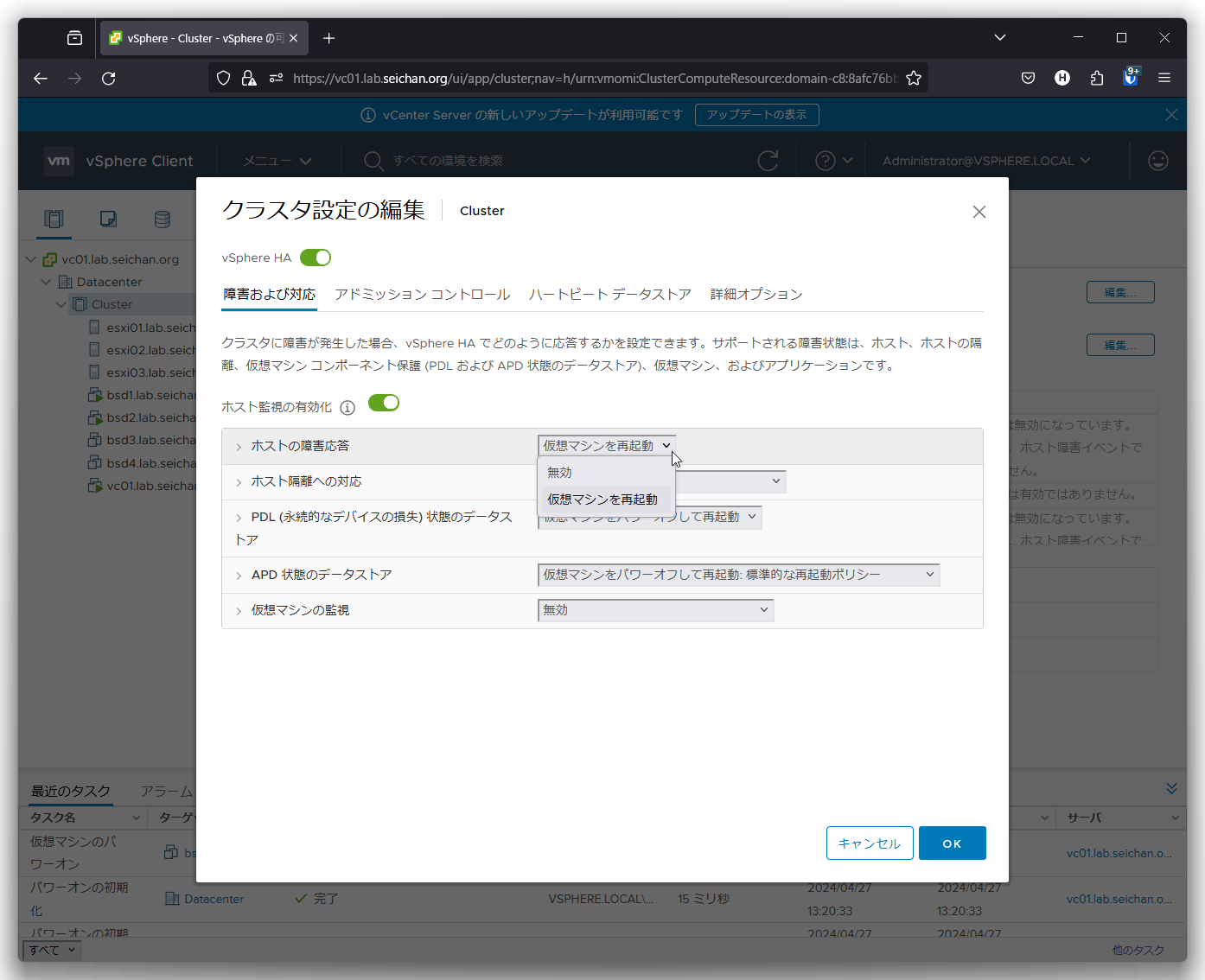
ホスト隔離への対応
ホストが隔離と判断された場合の挙動を設定します.
- 無効
デフォルト値です.隔離と判断された場合に仮想マシン操作は行いません - 仮想マシンをパワーオフして再起動
仮想マシンをパワーオフ (強制的に電源切断) を行って他のホストで起動します - 仮想マシンをシャットダウンして再起動
仮想マシンをシャットダウンして他のホストで起動します.この動作を行うには対象の仮想マシンで VMware Tools が動作している必要があります
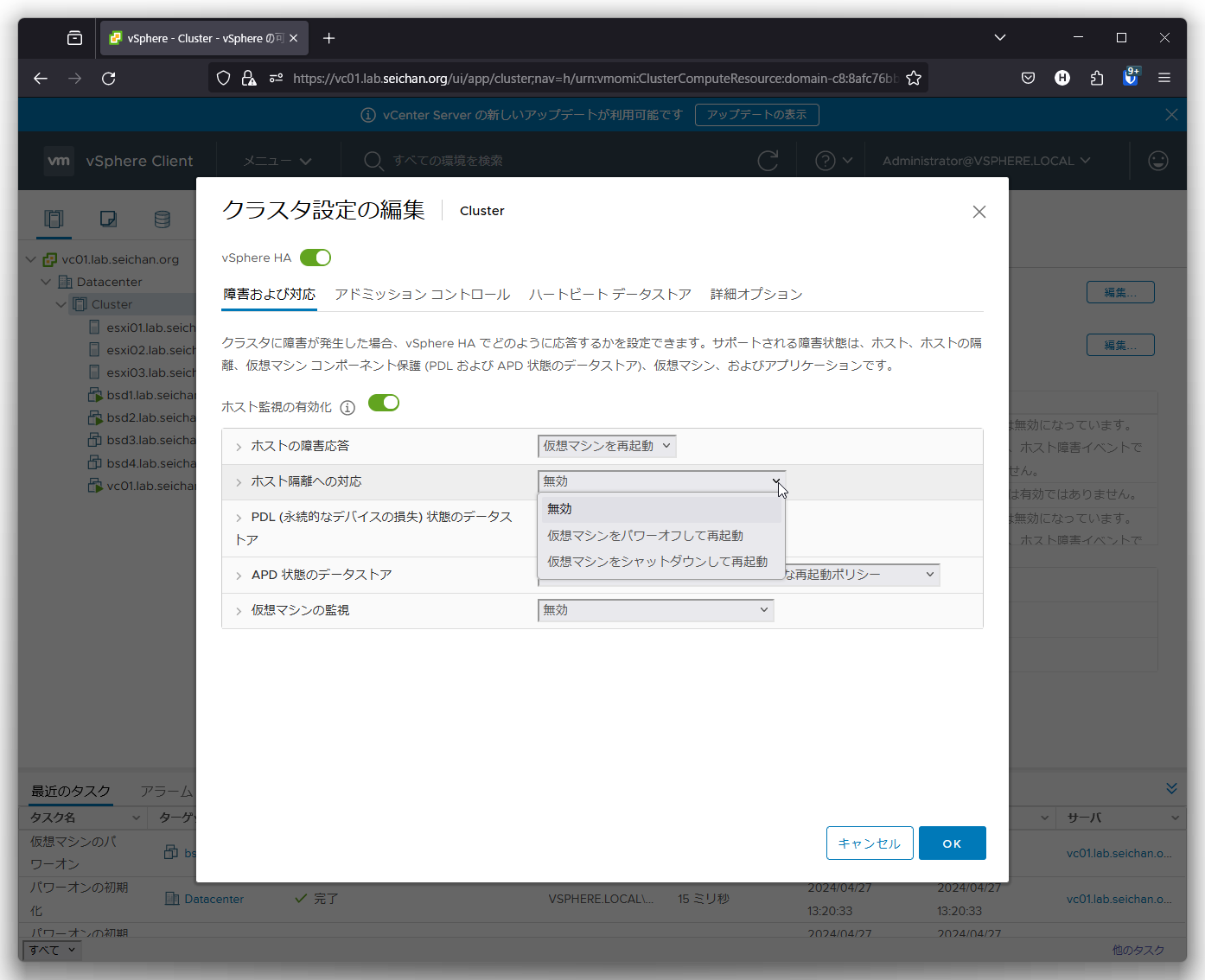
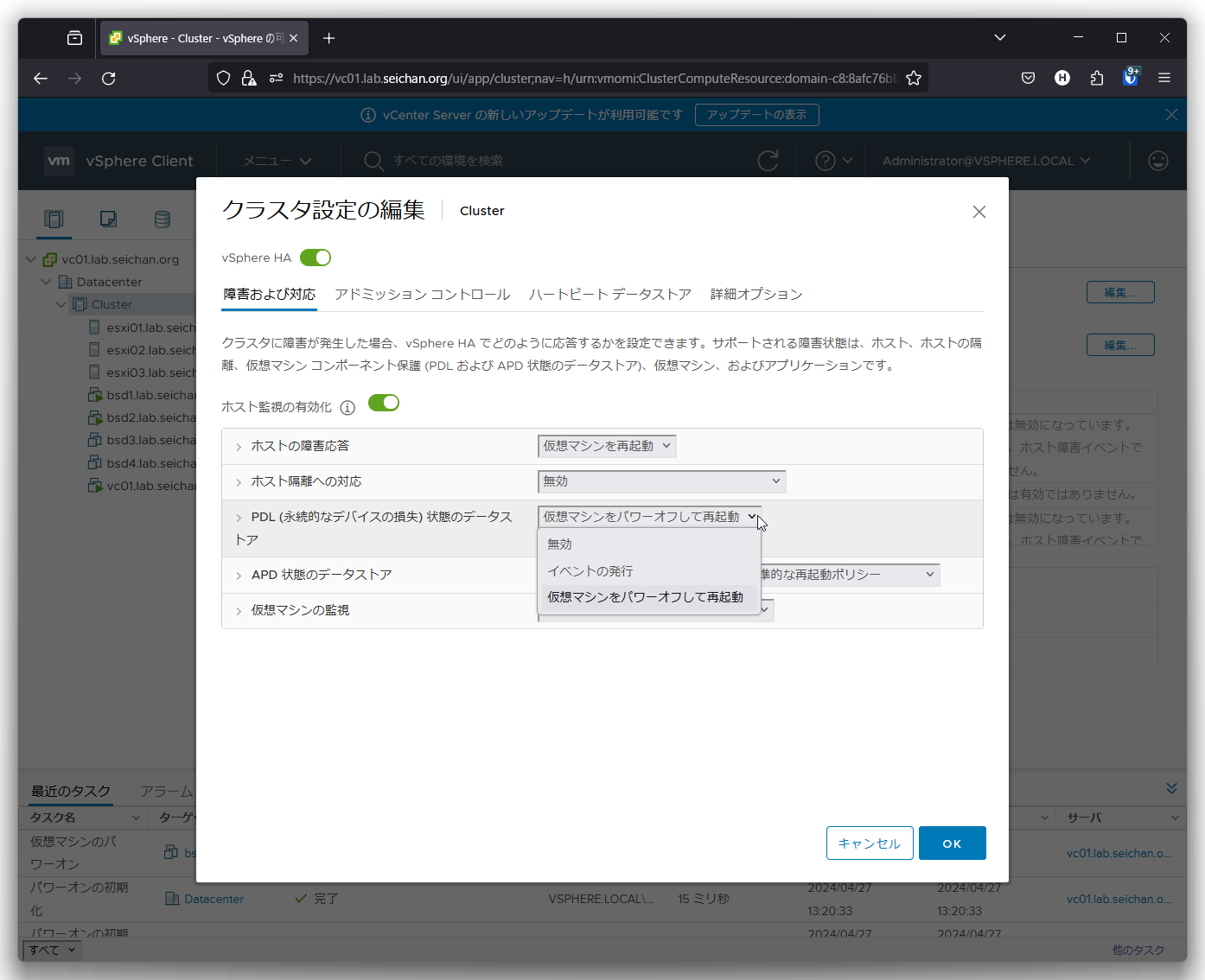
PDL (永続的なデバイスの損失) 状態のデータストア
PDL が発生した際の仮想マシンの挙動を設定します.
- 無効
何もアクションを起こしません - イベントの発行
vCenter Server にイベントを通知します - 仮想マシンをパワーオフして再起動
デフォルト値です.仮想マシンをパワーオフ (強制的に電源切断) を行って他のホストで起動します
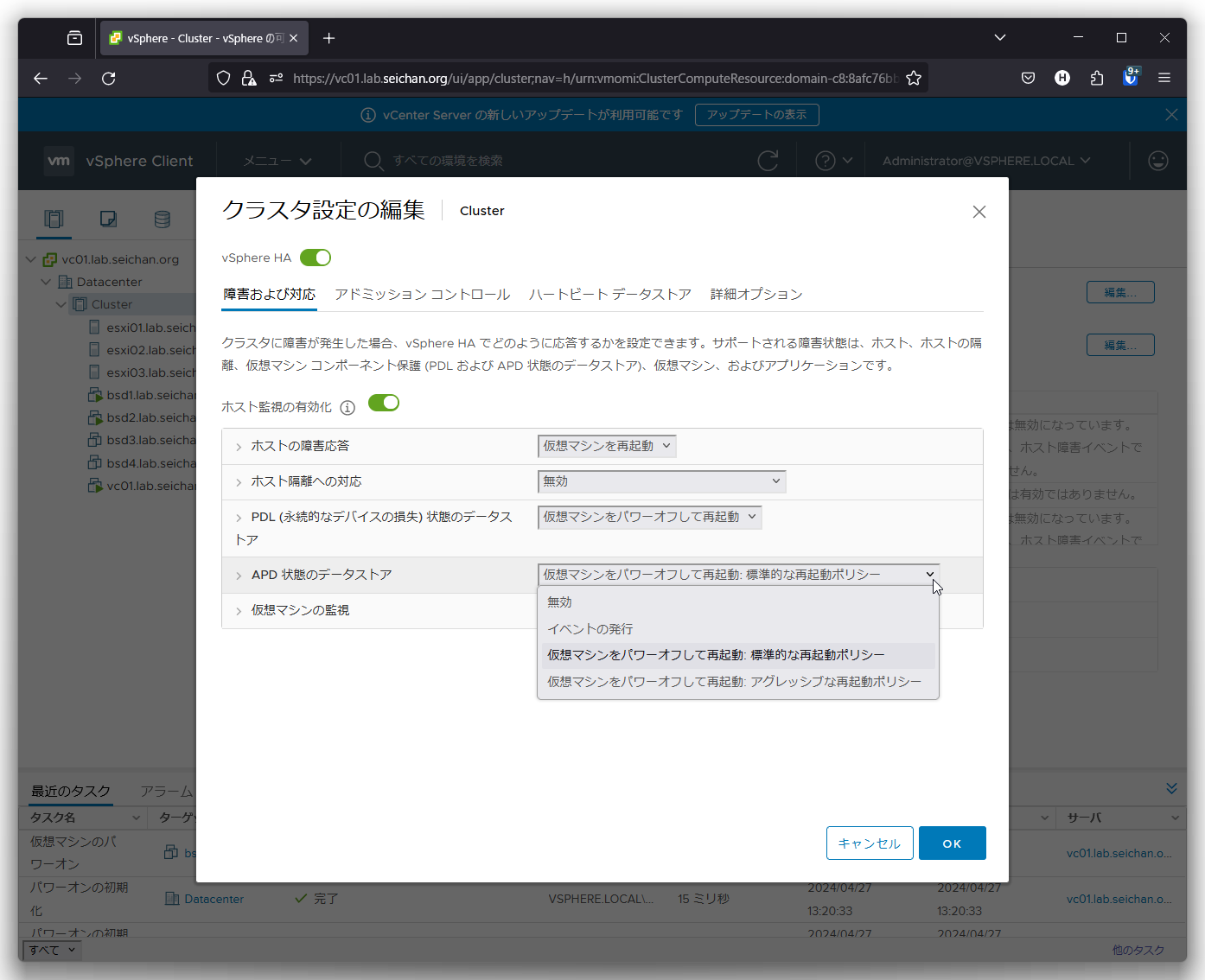
APD 状態のデータストア
APD が発生した際の仮想マシンの挙動を設定します
- 無効
何もアクションを起こしません - イベントの発行
vCenter Server にイベントを通知します - 仮想マシンをパワーオフして再起動 標準的な再起動ポリシー
デフォルト値です.他のホストで起動可能と判断した場合に仮想マシンをパワーオフ (強制的に電源切断) を行って他のホストで起動します. - 仮想マシンをパワーオフして再起動 アグレッシブな再起動ポリシー
他のホストで起動可能と判断できない場合でも仮想マシンをパワーオフ (強制的に電源切断) を行って他のホストで起動します.
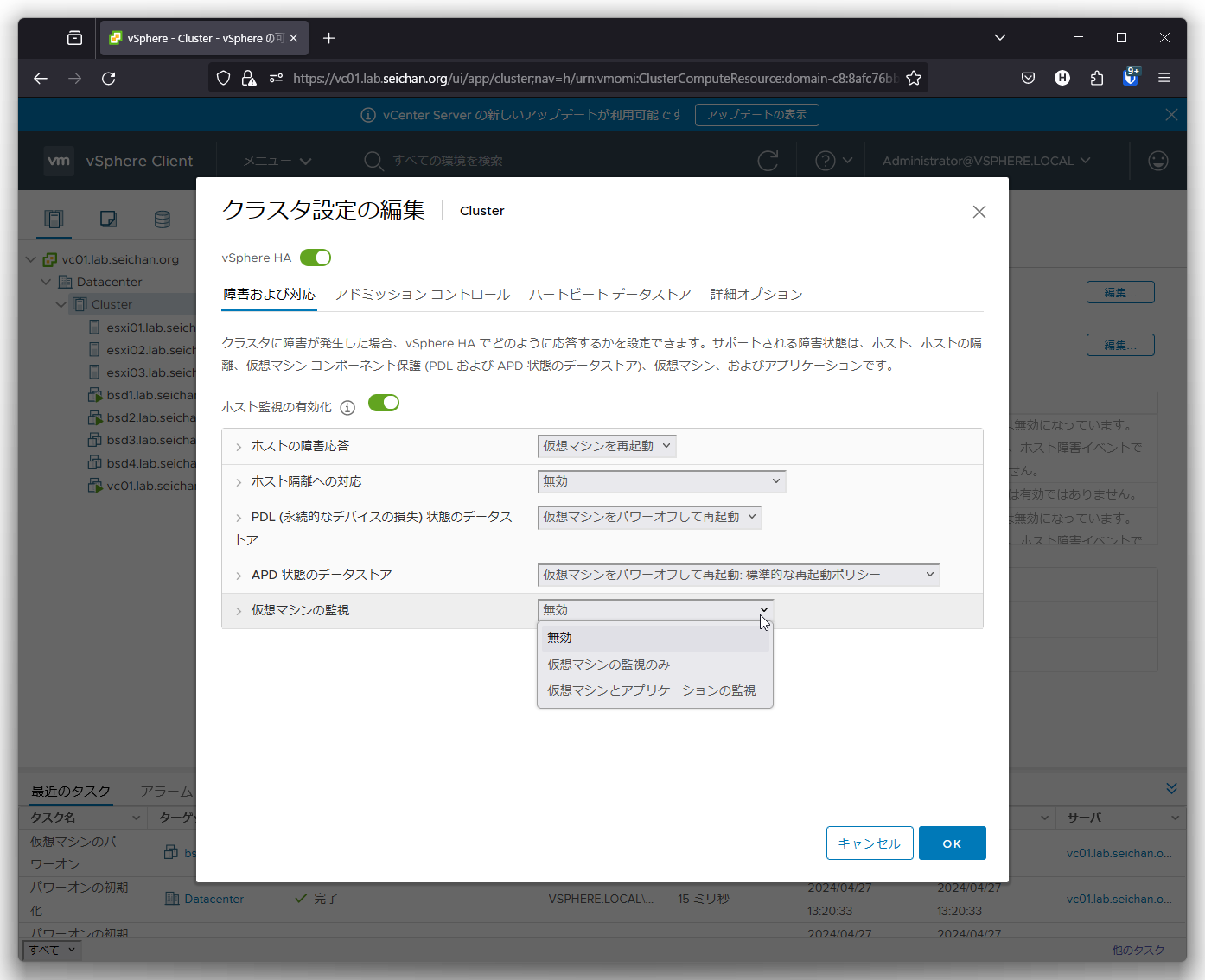
仮想マシンの監視
仮想マシンのハートビートが途絶えた場合の挙動を設定します.
- 無効
デフォルト値です.何もアクションを起こしません - 仮想マシンの監視のみ
ハートビートが途絶えた場合,同じホストの上で再起動を行います - 仮想マシンとアプリケーションの監視
ハートビートが途絶えた場合,同じホストの上で再起動を行います
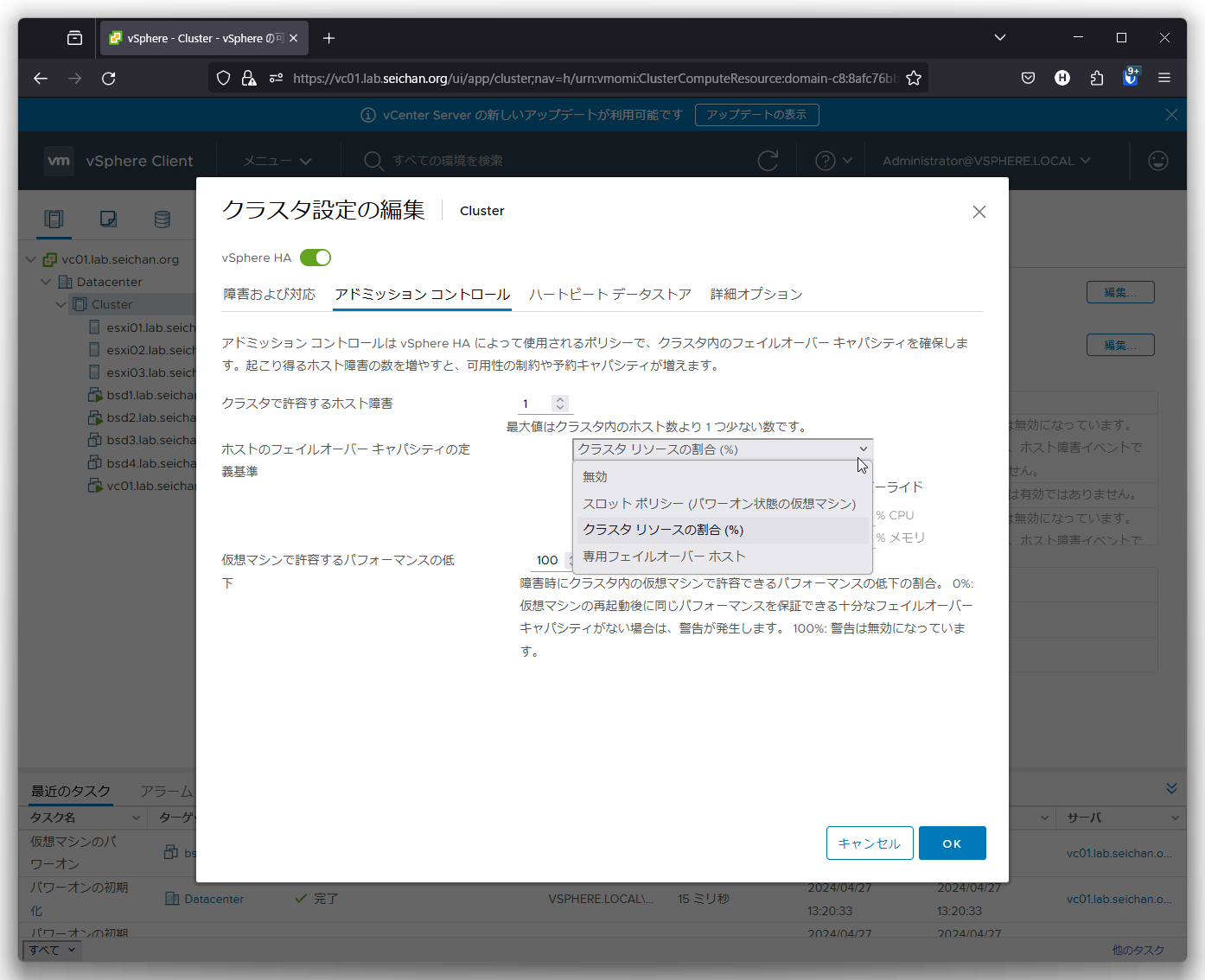
アドミッションコントロール
「アドミッションコントロール」は vSphere HA の挙動を制御するポリシーで,クラスター内のフェイルオーバーキャパシティを確保するために用いられます.
障害が発生すると利用可能なリソースが減るため,障害を前提としてリソースを計算することでリソース不足を起こさないようにすることが目的です.
クラスタで許容するホスト障害
クラスター内で障害を許容する台数を指定します.「1」を設定した場合は1台分の障害を考慮したリソース計算を行います.台数が多い程使用可能なクラスターリソースは減ります.
ホストのフェイルオーバーキャパシティの定義基準
アドミッションコントロールでの障害時のリソース予約のコントロールをどのように行うのかを制御します.
- 無効
アドミッションコントロールを無効にし,障害発生時のリソース低下を計算しません.仮想マシンを可能な限り立ち上げようとしますが,オーバーコミットが発生する可能性があります. - スロットポリシー (パワーオン状態の仮想マシン)
仮想マシンおよびホストの CPU とメモリーを「スロット」に計算してリソースを確保する計算方式です.クラスタリソースの割合や専用フェイルオーバーホストと比べて分かりづらい方式です.
詳細は「スロット ポリシー アドミッション コントロール」を参照してください. - クラスタリソースの割合 (%)
デフォルト値です.クラスターのリソースから障害ホスト分のリソース割合を差し引く計算方式です.3台のクラスターで障害の許容数が「1」の場合は 33% が障害分のリソースとなります.
4台のクラスターで許容数が「1」の場合は 25% が障害分のリソースとなります. - 専用フェイルオーバーホスト
フェイルオーバー専用のホストを用意する方式です.このモードを選択すると通常時フェイルオーバーホストには仮想マシンは一切稼働しません.障害許容数分フェイルオーバーホストが生成されます.
仮想マシンで許容するパフォーマンスの低下
障害が起きた際にクラスター内の仮想マシン群でパフォーマンスの低下を許容できる割合を指定します.
0% の場合,仮想マシンのフェイルオーバーの際にパフォーマンスを保証できない場合は警告を行います.
100% の場合警告を行いません.
ハートビートデータストア
vSpere HA において,ネットワークのハートビート障害が発生した際に,データストアでのハートビートを使用してホストおよび仮想マシンんを監視します.ここではハートビートで使用するデータストアを選択します.
ハートビートデータストアは最低2つ必要で,1つの場合は警告が表示されます.
- ホストからアクセス可能なデータストアを自動的に選択します
リストに関係なく,vCenter Server が自動的にデータストアを選択します - 指定したリストからのデータストアのみを使用する
明示的に指定したデータストアのみを使用します - 指定したリストからのデータストアを使用し,必要に応じて自動的に補足する
デフォルト値です.上の二つのいい所どりをした形で指定も可能ですし,不足していれば自動的に追加で選択されます.
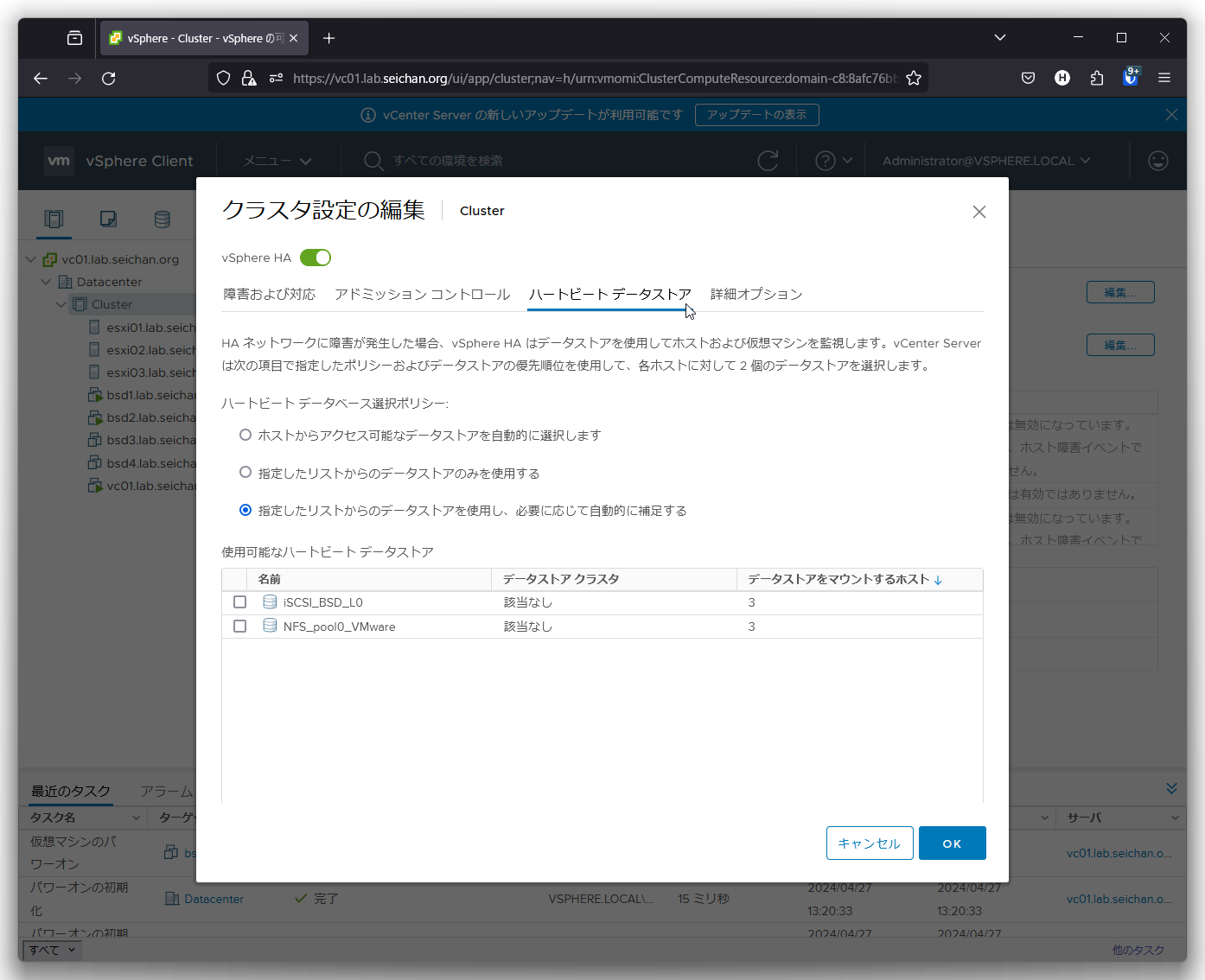
今回は上記を全てデフォルト値のままにしている状態で設定を行いました.
vSphere HA の状態確認
設定を完了した後,vSphere HA に必要なエージェントの導入や構成が行われます.完了したら「ホストおよびクラスタ」より vSphere HA を設定するクラスターを選択,画面中央の「監視」をクリック,「vSphere HA」-「サマリ」を選択ステータスを確認することができます.
マスター (プライマリー) に選択されているホストおよび,マスターに接続されたホスト (セカンダリー) の台数を確認しましょう.
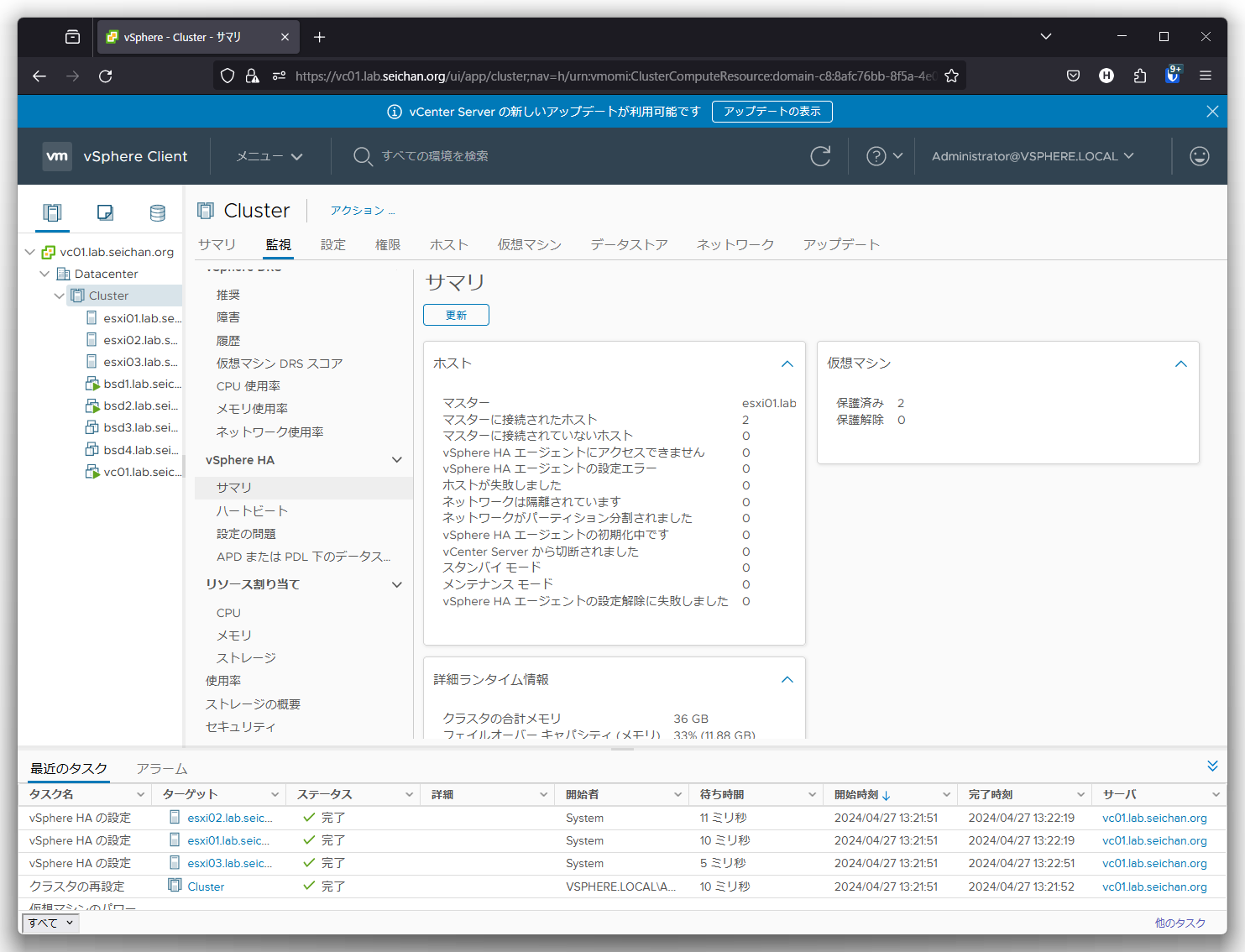
以上,vSphere HA の設定の解説でした.
次回は vSphere HA を有効にしている際の様々な障害とその際の動作について纏めます.
コメント